セマンティックセグメンテーションは、画像系ディープラーニングの一種で、画素レベルでそれが何かを認識するタスクを行う手法です。

やっていることは割りと簡単で、画像分類のタスクでは、画素情報をクラスの次元に落とし込んでいましたが、セマンティックセグメンテーションでは、それを画素(ピクセル)単位で行うようにしているだけです。
画像分類を実装したことがある人であれば、仕組みはすぐ理解できると思います。
ただし、当然教師あり学習ですので、上記のように、ピクセルごとにそれが何かをラベル付け(アノテーション)されていないと学習できません。
例えば、公開されているデータセットではなく、社内データなどでこういった教師データを作成したい場合には、大変な作業になると思います。
そこで、完全自動化までは不可能でも、教師なし学習である程度アノテーションの補助はできるようにならないかを考えてみます。
例えば、RGB情報(色)でのクラスタリングや、学習済みモデルによる転移学習で、ある程度、画素レベルの特徴分けができるかをやってみます。
今回は、上記のようなドライブレコーダーの画像において、白線を教師なしでアノテーションできるか実装してみます。
まぁ色々と調べた結果、車には色々とセンサーが組み込まれており、白線に関してもセンサーを用いる方が確実なようですが、今回もただの興味本位ですので、ひとまず画像で頑張ってみます。
CamVid
ドライブレコーダーの画像が必要ですので、今回は下記のCamVidデータセットを使います。
CamVid: http://mi.eng.cam.ac.uk/research/projects/VideoRec/CamVid/
セマンティックセグメンテーション用のデータセットで、700枚程度のドライブレコーダー画像に、空、建物、木、道路、車など32クラスのアノテーションがされています。
今回は画像のみを使いますので、アノテーションデータは使いません。
試しに、一枚だけ表示させてみます。
import glob
import numpy as np
import pandas as pd
import matplotlib
import matplotlib.pylab as plt
%matplotlib inline
from PIL import Image
imgs = glob.glob('./CamVid/images/*.jpg')
img_org = imgs[0]
img_org = Image.open(img_org)
plt.imshow(img_org)
plt.show()

こういった画像の画素情報からうまく特徴を掴んで白線をアノテーションできるか頑張ってみます。
ところで、ここのデータセットはライセンス情報が見当たらないのですが、商用利用は可能なのだろうか。
ブログでやっている分には多分大丈夫だと思うんですが...。
スーパーピクセル色平均による白線認識
まずはRGB情報でクラスタリングできるか考えてみます。
ただし、ピクセル単位だと要素が細かすぎるため、スーパーピクセルを使ってみます。
スーパーピクセルは、画像のエッジ情報を考慮して、構造的に意味のある一連の領域に大まかに分割することができます。
Pythonでのスーパーピクセル化は、scikit-imageを使って行うことができます。
import skimage
import skimage.segmentation
target_i = 0
fig, axs = plt.subplots(ncols=3, figsize=(15, 20))
img_org = imgs[target_i]
img_org = skimage.util.img_as_float(plt.imread(img_org))
superpixcels = skimage.segmentation.slic(img_org, 500)
axs[0].imshow(img_org)
axs[1].imshow(superpixcels)
axs[2].imshow(skimage.segmentation.mark_boundaries(img_org, superpixcels))
plt.show()
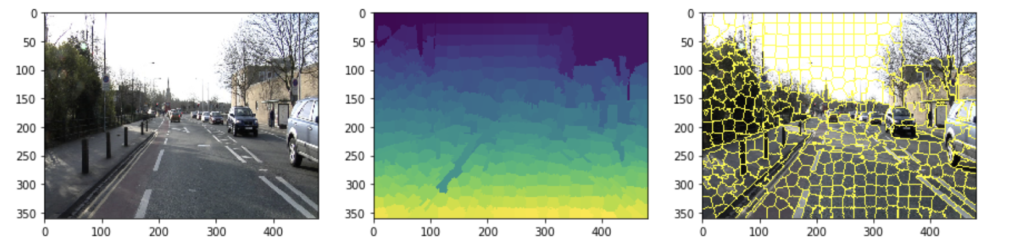
エッジ情報をどう使うかといった詳しいことは分かりませんが、白線などは確かに領域として取れていそうなので使えそうです。
まずはこのスーパーピクセルごとに色平均を取って可視化してみます。
target_i = 0
fig, axs = plt.subplots(ncols=2, figsize=(10, 20))
img_org = imgs[target_i]
superpixcels = skimage.segmentation.slic(skimage.util.img_as_float(plt.imread(img_org)), 500)
img_org = Image.open(img_org)
axs[0].imshow(img_org)
axs[0].set_title('org')
img_tmp = np.array(img_org)
for superpixcel_class in np.unique(superpixcels):
target = np.where(superpixcels == superpixcel_class)
r = [img_tmp[h, w, 0] for h, w in zip(target[0], target[1])]
g = [img_tmp[h, w, 1] for h, w in zip(target[0], target[1])]
b = [img_tmp[h, w, 2] for h, w in zip(target[0], target[1])]
r_mean = np.mean(r)
g_mean = np.mean(g)
b_mean = np.mean(b)
for h, w in zip(target[0], target[1]):
img_tmp[h, w, 0] = r_mean
img_tmp[h, w, 1] = g_mean
img_tmp[h, w, 2] = b_mean
img_rgb_mean_superpixcels = Image.fromarray(img_tmp)
axs[1].imshow(img_rgb_mean_superpixcels)
axs[1].set_title('rgb mean / super pixcels')
plt.show()
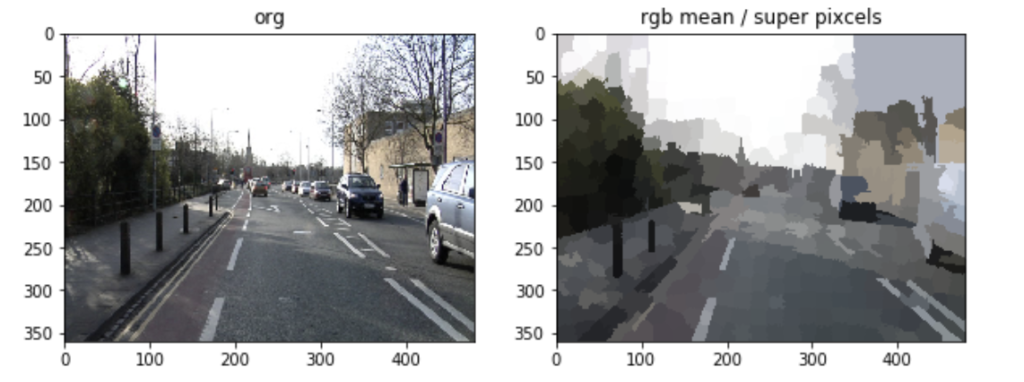
やはり白線はしっかりと形が取れていそうですね。
この情報から、白線部分のみを取りたいと考えます。
そこで、次のような手順を踏んでみます。
- 先程のスーパーピクセルごとの色平均の情報を、グレースケール化
- 白線のみが取れれば良いので、画像の下半分のみにクロップ
- 教師なしクラスタリングで2クラスに分類
- 分類されたピクセルのクラスごとの色(グレースケール)平均を取って、より白に近い方のクラスを白線クラスと決定
実際に行って画像を確認してみます。
from sklearn.mixture import GaussianMixture
target_i = 0
fig, axs = plt.subplots(ncols=3, figsize=(15, 20))
img_org = imgs[target_i]
superpixcels = skimage.segmentation.slic(skimage.util.img_as_float(plt.imread(img_org)), 500)
img_org = Image.open(img_org)
size = img_org.size
axs[0].imshow(img_org)
axs[0].set_title('org')
img_tmp = np.array(img_org)
for superpixcel_class in np.unique(superpixcels):
target = np.where(superpixcels == superpixcel_class)
r = [img_tmp[h, w, 0] for h, w in zip(target[0], target[1])]
g = [img_tmp[h, w, 1] for h, w in zip(target[0], target[1])]
b = [img_tmp[h, w, 2] for h, w in zip(target[0], target[1])]
r_mean = np.mean(r)
g_mean = np.mean(g)
b_mean = np.mean(b)
for h, w in zip(target[0], target[1]):
img_tmp[h, w, 0] = r_mean
img_tmp[h, w, 1] = g_mean
img_tmp[h, w, 2] = b_mean
img_rgb_mean_superpixcels = Image.fromarray(img_tmp)
axs[1].imshow(img_rgb_mean_superpixcels)
axs[1].set_title('rgb mean / super pixcels')
img_tmp = img_rgb_mean_superpixcels.convert('L')
img_tmp = img_tmp.crop((0, size[1]//2, size[0], size[1]))
img_tmp = np.array(img_tmp)
img_tmp_for_gmm1 = img_tmp.flatten()
img_tmp_for_gmm2 = img_tmp_for_gmm1.reshape(-1, 1)
gmm = GaussianMixture(n_components=2, covariance_type='full').fit(img_tmp_for_gmm2)
gmm = gmm.predict(img_tmp_for_gmm2).astype(np.float32)
class_a = gmm
class_b = -(gmm-1)
class_a_rgb = img_tmp_for_gmm1*class_a
class_b_rgb = img_tmp_for_gmm1*class_b
if (class_a_rgb.sum()/np.nonzero(class_a_rgb)[0].size) > (class_b_rgb.sum()/np.nonzero(class_b_rgb)[0].size):
target_class = class_a
else:
target_class = class_b
img_tmp = target_class.reshape(size[1]//2, size[0])
img_tmp *= 255
img_tmp = Image.fromarray(img_tmp)
overlay = Image.new(img_tmp.mode, size, 'black')
overlay.paste(img_tmp, (0, size[1]//2))
axs[2].imshow(overlay)
axs[2].set_title('gmm')
plt.show()

この画像に関しては、光の影響で、白線以外も色々と取れてきているようです。
ここをもっと多クラスに分類した上で、クラスごとの色平均が一番高いクラスにしてみたり、今回は白が集中している部分をクラス化してくれればと思って、分散もパラメータに含む混合ガウスモデルによるクラスタリングにしましたが、k-means法などの他のクラスタリングにしてみるなど、やりようは考えられそうですが、ひとまずこのままやってみます。
実際に重ね合わせてみて、どのくらいアノテーションできていそうか確認してみます。
from PIL import ImageOps
target_i = 0
img_org = imgs[target_i]
superpixcels = skimage.segmentation.slic(skimage.util.img_as_float(plt.imread(img_org)), 500)
img_org = Image.open(img_org)
size = img_org.size
img_tmp = np.array(img_org)
for superpixcel_class in np.unique(superpixcels):
target = np.where(superpixcels == superpixcel_class)
r = [img_tmp[h, w, 0] for h, w in zip(target[0], target[1])]
g = [img_tmp[h, w, 1] for h, w in zip(target[0], target[1])]
b = [img_tmp[h, w, 2] for h, w in zip(target[0], target[1])]
r_mean = np.mean(r)
g_mean = np.mean(g)
b_mean = np.mean(b)
for h, w in zip(target[0], target[1]):
img_tmp[h, w, 0] = r_mean
img_tmp[h, w, 1] = g_mean
img_tmp[h, w, 2] = b_mean
img_rgb_mean_superpixcels = Image.fromarray(img_tmp)
img_tmp = img_rgb_mean_superpixcels.convert('L')
img_tmp = img_tmp.crop((0, size[1]//2, size[0], size[1]))
img_tmp = np.array(img_tmp)
img_tmp_for_gmm1 = img_tmp.flatten()
img_tmp_for_gmm2 = img_tmp_for_gmm1.reshape(-1, 1)
gmm = GaussianMixture(n_components=2, covariance_type='full').fit(img_tmp_for_gmm2)
gmm = gmm.predict(img_tmp_for_gmm2).astype(np.float32)
class_a = gmm
class_b = -(gmm-1)
class_a_rgb = img_tmp_for_gmm1*class_a
class_b_rgb = img_tmp_for_gmm1*class_b
if (class_a_rgb.sum()/np.nonzero(class_a_rgb)[0].size) > (class_b_rgb.sum()/np.nonzero(class_b_rgb)[0].size):
target_class = class_a
else:
target_class = class_b
img_tmp = target_class.reshape(size[1]//2, size[0])
img_tmp *= 255
img_tmp = Image.fromarray(img_tmp)
overlay = Image.new(img_tmp.mode, size, 'black')
overlay.paste(img_tmp, (0, size[1]//2))
overlay = ImageOps.grayscale(overlay)
overlay = ImageOps.colorize(overlay, black=(0, 0, 0), white=(0, 255, 255))
blended = Image.blend(img_org, overlay, 0.3)
plt.imshow(blended)
plt.show()
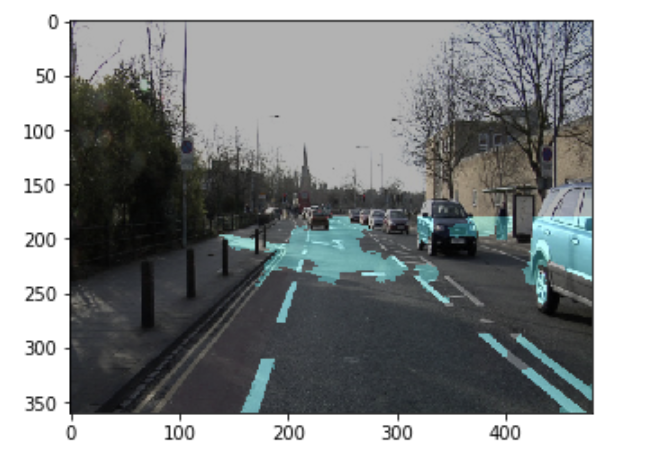
アノテーションの補助ができればというレベルで良いと考えれば、そこまで変では無さそうな感じでしょうか?
もちろん、完全自動化がアウトなのは、この時点で一目瞭然ですが笑
さて、これを何枚かに実施してみます。
「これは割りとマシかな?」と思えるものをピックアップしてみました。


ただし、全体的には、やはりうまくいかないものが多く、補助といえば補助になりそうですが、もう少し力を上げたいところです。
そこで今度は、ある程度画像の特徴を捉えることができる学習済みモデルによる転移学習を試してみます。
ResNet152
今回使うモデルはResNetにしました。
ResNet(Deep Residual Net)は、Microsoftが開発したモデルで、ILSVRC2015という物体認識コンペで最高性能を出したモデルになります。
論文が下記になります。
Deep Residual Learning for Image Recognition: https://arxiv.org/pdf/1512.03385v1.pdf
ResNetの仕組みの解説などについては、下記などが参考になると思います。
このモデルについても、Chainerで実装されていますので、今回もChainerから使ってみます。
学習済みモデルの重みについては、以下からダウンロードできます。
- https://github.com/KaimingHe/deep-residual-networks
重みファイルをChainer指定のフォルダに配置して、モデルインスタンスを作成することができます。
import chainer
from chainer.training import extensions
import chainer.functions as F
import chainer.links as L
resnet152 = L.ResNet152Layers()
VGGの時と同様に、 L.model.vision.resnet.prepare で画像をResNetが読み込める形式に変換して、ネットワークの各レイヤーの特徴量を取ってくることができます。
target_i = 0
img_org = imgs[target_i]
img_org = Image.open(img_org)
x = L.model.vision.resnet.prepare(img_org)[np.newaxis]
layers = resnet152.extract(x, layers=['conv1', 'res2', 'res3', 'res4', 'res5', 'pool5'])
for k in layers.keys():
print(k, layers[k].data.shape)
"""
pool5 (1, 2048)
res5 (1, 2048, 7, 7)
res3 (1, 512, 28, 28)
res4 (1, 1024, 14, 14)
conv1 (1, 64, 112, 112)
res2 (1, 256, 56, 56)
"""
学習済みResNet特徴量による白線認識
転移学習で画素ごとの特徴量を取得したい場合、畳み込み層が入るほど、画像としての解像度は落ちるので、上層の畳み込み層での特徴量を抽出します。
今回は conv1 の特徴量について、出力チャンネル数の次元分だけ特徴を得られますので、これをそれぞれ可視化してみて、どの次元が地面だったり白いものなどを捉えていそうかを確認してみます。
from sklearn.preprocessing import MinMaxScaler
target_i = 0
img_org = imgs[target_i]
img_org = Image.open(img_org)
size = img_org.size
x = L.model.vision.resnet.prepare(img_org)[np.newaxis]
layers = resnet152.extract(x, layers=['conv1', 'res2', 'res3', 'res4', 'res5', 'pool5'])
feature = layers['conv1'].data.squeeze().transpose(1, 2, 0)
for i in range(0, 64, 4):
fig, axs = plt.subplots(ncols=4, figsize=(20, 20))
for j in range(4):
feature_tmp = feature[:, :, i+j].reshape(112, 112)
feature_tmp = MinMaxScaler().fit_transform(feature_tmp)
feature_tmp *= 255
img_feature = Image.fromarray(feature_tmp)
img_feature = img_feature.resize(size)
axs[j].imshow(img_feature)
axs[j].set_title(i+j)
plt.show()

※以下、64次元まで続く
さて、この中から、白線部分が光っている次元をいくつか選び、特徴量の平均を取ることにします。
以降は、色(RGB)の時と同様です。
target_channels = [32, 35, 55]
target_i = 0
fig, axs = plt.subplots(ncols=4, figsize=(20, 20))
img_org = imgs[target_i]
superpixcels = skimage.segmentation.slic(skimage.util.img_as_float(plt.imread(img_org)), 500)
img_org = Image.open(img_org)
size = img_org.size
axs[0].imshow(img_org)
axs[0].set_title('org')
x = L.model.vision.resnet.prepare(img_org)[np.newaxis]
layers = resnet152.extract(x, layers=['conv1', 'res2', 'res3', 'res4', 'res5', 'pool5'])
feature = layers['conv1'].data.squeeze().transpose(1, 2, 0)
feature = feature[:, :, target_channels]
feature = np.mean(feature, axis=2)
feature = MinMaxScaler().fit_transform(feature)
feature *= 255
img_feature = Image.fromarray(feature)
img_feature = img_feature.resize(size)
axs[1].imshow(img_feature)
axs[1].set_title('feature mean')
img_tmp = np.array(img_feature)
for superpixcel_class in np.unique(superpixcels):
target = np.where(superpixcels == superpixcel_class)
feature_tmp = [img_tmp[h, w] for h, w in zip(target[0], target[1])]
feature_mean = np.mean(feature_tmp)
for h, w in zip(target[0], target[1]):
img_tmp[h, w] = feature_mean
img_feature_mean_superpixcels = Image.fromarray(img_tmp)
axs[2].imshow(img_feature_mean_superpixcels)
axs[2].set_title('feature mean / super pixcels')
img_tmp = img_feature_mean_superpixcels.convert('L')
img_tmp = img_tmp.crop((0, size[1]//2, size[0], size[1]))
img_tmp = np.array(img_tmp)
img_tmp_for_gmm1 = img_tmp.flatten()
img_tmp_for_gmm2 = img_tmp_for_gmm1.reshape(-1, 1)
gmm = GaussianMixture(n_components=2, covariance_type='full').fit(img_tmp_for_gmm2)
gmm = gmm.predict(img_tmp_for_gmm2).astype(np.float32)
class_a = gmm
class_b = -(gmm-1)
class_a_rgb = img_tmp_for_gmm1*class_a
class_b_rgb = img_tmp_for_gmm1*class_b
if (class_a_rgb.sum()/np.nonzero(class_a_rgb)[0].size) > (class_b_rgb.sum()/np.nonzero(class_b_rgb)[0].size):
target_class = class_a
else:
target_class = class_b
img_tmp = target_class.reshape(size[1]//2, size[0])
img_tmp *= 255
img_tmp = Image.fromarray(img_tmp)
overlay = Image.new(img_tmp.mode, size, 'black')
overlay.paste(img_tmp, (0, size[1]//2))
axs[3].imshow(overlay)
axs[3].set_title('gmm')
plt.show()

んー?
結構色々と取ってきてしまいそうですね。
何枚か実施してみます。


やはり、他にも色んなものを取ってきてしまうようですね。
むしろ、道路や車などの方が効果はあるかもしれません。
といっても、色平均の時とそこまで変わらない感じなので、使うタスクによっては転移学習で色々出力してみるのもアリかもしれないという印象でした。
ついでに、RGBの特徴量の時も、ResNetの特徴量の時も2値化していますので、それで積集合を取って重ねてみました。
target_channels = [32, 35, 55]
target_i = 0
img_org = imgs[target_i]
superpixcels = skimage.segmentation.slic(skimage.util.img_as_float(plt.imread(img_org)), 500)
img_org = Image.open(img_org)
size = img_org.size
img_tmp = np.array(img_org)
for superpixcel_class in np.unique(superpixcels):
target = np.where(superpixcels == superpixcel_class)
r = [img_tmp[h, w, 0] for h, w in zip(target[0], target[1])]
g = [img_tmp[h, w, 1] for h, w in zip(target[0], target[1])]
b = [img_tmp[h, w, 2] for h, w in zip(target[0], target[1])]
r_mean = np.mean(r)
g_mean = np.mean(g)
b_mean = np.mean(b)
for h, w in zip(target[0], target[1]):
img_tmp[h, w, 0] = r_mean
img_tmp[h, w, 1] = g_mean
img_tmp[h, w, 2] = b_mean
img_rgb_mean_superpixcels = Image.fromarray(img_tmp)
img_tmp = img_rgb_mean_superpixcels.convert('L')
img_tmp = img_tmp.crop((0, size[1]//2, size[0], size[1]))
img_tmp = np.array(img_tmp)
img_tmp_for_gmm1 = img_tmp.flatten()
img_tmp_for_gmm2 = img_tmp_for_gmm1.reshape(-1, 1)
gmm = GaussianMixture(n_components=2, covariance_type='full').fit(img_tmp_for_gmm2)
gmm = gmm.predict(img_tmp_for_gmm2).astype(np.float32)
class_a = gmm
class_b = -(gmm-1)
class_a_rgb = img_tmp_for_gmm1*class_a
class_b_rgb = img_tmp_for_gmm1*class_b
if (class_a_rgb.sum()/np.nonzero(class_a_rgb)[0].size) > (class_b_rgb.sum()/np.nonzero(class_b_rgb)[0].size):
target_class = class_a
else:
target_class = class_b
overlay_rgb_tmp = target_class.reshape(size[1]//2, size[0])
x = L.model.vision.resnet.prepare(img_org)[np.newaxis]
layers = resnet152.extract(x, layers=['conv1', 'res2', 'res3', 'res4', 'res5', 'pool5'])
feature = layers['conv1'].data.squeeze().transpose(1, 2, 0)
feature = feature[:, :, target_channels]
feature = np.mean(feature, axis=2)
feature = MinMaxScaler().fit_transform(feature)
feature *= 255
img_feature = Image.fromarray(feature)
img_feature = img_feature.resize(size)
img_tmp = np.array(img_feature)
for superpixcel_class in np.unique(superpixcels):
target = np.where(superpixcels == superpixcel_class)
feature_tmp = [img_tmp[h, w] for h, w in zip(target[0], target[1])]
feature_mean = np.mean(feature_tmp)
for h, w in zip(target[0], target[1]):
img_tmp[h, w] = feature_mean
img_feature_mean_superpixcels = Image.fromarray(img_tmp)
img_tmp = img_feature_mean_superpixcels.convert('L')
img_tmp = img_tmp.crop((0, size[1]//2, size[0], size[1]))
img_tmp = np.array(img_tmp)
img_tmp_for_gmm1 = img_tmp.flatten()
img_tmp_for_gmm2 = img_tmp_for_gmm1.reshape(-1, 1)
gmm = GaussianMixture(n_components=2, covariance_type='full').fit(img_tmp_for_gmm2)
gmm = gmm.predict(img_tmp_for_gmm2).astype(np.float32)
class_a = gmm
class_b = -(gmm-1)
class_a_rgb = img_tmp_for_gmm1*class_a
class_b_rgb = img_tmp_for_gmm1*class_b
if (class_a_rgb.sum()/np.nonzero(class_a_rgb)[0].size) > (class_b_rgb.sum()/np.nonzero(class_b_rgb)[0].size):
target_class = class_a
else:
target_class = class_b
overlay_feature_tmp = target_class.reshape(size[1]//2, size[0])
overlay_tmp = overlay_rgb_tmp * overlay_feature_tmp
overlay_tmp *= 255
overlay_tmp = Image.fromarray(overlay_tmp)
overlay = Image.new(overlay_tmp.mode, size, 'black')
overlay.paste(overlay_tmp, (0, size[1]//2))
overlay = ImageOps.grayscale(overlay)
overlay = ImageOps.colorize(overlay, black=(0, 0, 0), white=(0, 255, 255))
blended = Image.blend(img_org, overlay, 0.3)
plt.imshow(blended)
plt.show()

何枚か実施してみた結果...



自信のあるところをカッチリと取るようになってきたような気がします。
まとめ
以上、スーパーピクセルと色の特徴量や学習済みモデルの特徴量を使って、教師なしでセグメンテーションをやってみました。
といっても、うまくいっているものを表示させていましたので、実はかなり酷いものもたくさんあります。
そのあたりも含め、より精度を高められる方法があればなーと思いました。
今回の白線のような、周囲と明らかに色が異なるものに関しては、色の特徴量は有効なように思います。
としても、冒頭に述べたように、やはり教師あり学習をさせたいところですので、アノテーションの補助ぐらいに使うのが良いのかなと思いました。
コメント