深層学習において文脈情報を学習させる方法としては、再帰的ニューラルネットワーク(RNN)を用いる方法と畳み込みニューラルネットワーク(CNN)を用いる方法があります。
今回はそれぞれの方法で、文章を学習させてラベル分類を行うモデルを、Chainerを使って実装しました。
RNNによる文章分類モデル
RNNは系列データを学習させることに適したニューラルネットワークです。
文章データは、文字や単語の時系列とみなすことができますので、文字や単語を値として捉えて文章の順番にしたがって入力することで、文脈情報を学習させることができます。
今回はネットから適当に拝借した英語の短文を用意し、それが質問かそうでないかを分類するモデルを実装してみました。
ここで、トリミングで記号を削除することで、「?」も削除することで、文脈情報のみから分類してみます。
data = [
["Could I exchange business cards, if you don’t mind?", 1],
["I'm calling regarding the position advertised in the newspaper.", 0],
["I'd like to apply for the programmer position.", 0],
["Could you tell me what an applicant needs to submit?", 1],
["Could you tell me what skills are required?", 1],
["We will assist employees with training and skill development.", 0],
["What kind of in-house training system do you have for your new recruits?", 1],
["For office equipment I think rental is better.", 0],
["Is promotion based on the seniority system?", 1],
["What's still pending from February?", 1],
["Which is better, rental or outright purchase?", 1],
["General Administration should do all the preparations for stockholder meetings.", 0],
["One of the elevators is out of order. When do you think you can have it fixed?", 1],
["General Administration is in charge of office building maintenance.", 0],
["Receptionists at the entrance hall belong to General Administration.", 0],
["Who is managing the office supplies inventory?", 1],
["Is there any difference in pay between males and females?", 1],
["The General Administration Dept. is in charge of office maintenance.", 0],
["Have you issued the meeting notice to shareholders?", 1],
["What is an average annual income in Japan?", 1],
["Many Japanese companies introduced the early retirement system.", 0],
["How much did you pay for the office equipment?", 1],
["Is the employee training very popular here?", 1],
["What kind of amount do you have in mind?", 1],
["We must prepare our financial statement by next Monday.", 0],
["Would it be possible if we check the draft?", 1],
["The depreciation of fixed assets amounts to $5 million this year.", 0],
["Please expedite the completion of the balance sheet.", 0],
["Could you increase the maximum lending limit for us?", 1],
["We should cut down on unnecessary expenses to improve our profit ratio.", 0],
["What percentage of revenue are we spending for ads?", 1],
["One of the objectives of internal auditing is to improve business efficiency.", 0],
["Did you have any problems finding us?", 1],
["How is your business going?", 1],
["Not really well. I might just sell the business.", 0],
["What line of business are you in?", 1],
["He has been a valued client of our bank for many years.", 0],
["Would you like for me to show you around our office?", 1],
["It's the second door on your left down this hall.", 0],
["This is the … I was telling you about earlier.", 0],
["We would like to take you out to dinner tonight.", 0],
["Could you reschedule my appointment for next Wednesday?", 1],
["Would you like Japanese, Chinese, Italian, French or American?", 1],
["Is there anything you prefer not to have?", 1],
["Please give my regards to the staff back in San Francisco.", 0],
["This is a little expression of our thanks.", 0],
["Why don’t you come along with us to the party this evening?", 1],
["Unfortunately, I have a prior engagement on that day.", 0],
["I am very happy to see all of you today.", 0],
["It is a great honor to be given this opportunity to present here.", 0],
["The purpose of this presentation is to show you the new direction our business is taking in 2009.", 0],
["Could you please elaborate on that?", 1],
["What's your proposal?", 1],
["That's exactly the point at issue here.", 0],
["What happens if our goods arrive after the delivery dates?", 1],
["I'm afraid that's not accpetable to us.", 0],
["Does that mean you can deliver the parts within three months?", 1],
["We can deliver parts in as little as 5 to 10 business days.", 0],
["We've considered all the points you've put forward and our final offer is $900.", 0],
["Excuse me but, could I have your name again, please?", 1],
["It's interesting that you'd say that.", 0],
["The pleasure's all ours. Thank you for coimng today.", 0],
["Could you spare me a little of your time?", 1],
["That's more your area of expertise than mine, so I'd like to hear more.", 0],
["I'd like to talk to you about the new project.", 0],
["What time is convenient for you?", 1],
["How’s 3:30 on Tuesday the 25th?", 1],
["Could you inform us of the most convenient dates for our visit?", 1],
["Fortunately, I was able to return to my office in time for the appointment.", 0],
["I am sorry, but we have to postpone our appointment until next month.", 0],
["Great, see you tomorrow then.", 0],
["Great, see you tomorrow then.", 1],
["I would like to call on you sometime in the morning.", 0],
["I'm terribly sorry for being late for the appointment.", 0],
["Could we reschedule it for next week?", 1],
["I have to fly to New York tomorrow, can we reschedule our meeting when I get back?", 1],
["I'm looking forward to seeing you then.", 0],
["Would you mind writing down your name and contact information?", 1],
["I'm sorry for keeping you waiting.", 0],
["Did you find your way to our office wit no problem?", 1],
["I need to discuss this with my superior. I'll get back to you with our answer next week.", 0],
["I'll get back to you with our answer next week.", 0],
["Thank you for your time seeing me.", 0],
["What does your company do?", 1],
["Could I ask you to make three more copies of this?", 1],
["We have appreciated your business.", 0],
["When can I have the contract signed?", 1],
["His secretary is coming down now.", 0],
["Please take the elevator on your right to the 10th floor.", 0],
["Would you like to leave a message?", 1],
["It's downstairs in the basement.", 0],
["Your meeting will be held at the main conference room on the 15th floor of the next building.", 0],
["Actually, it is a bit higher than expected. Could you lower it?", 1],
["We offer the best price anywhere.", 0],
["All products come with a 10-year warranty.", 0],
["It sounds good, however, is made to still think; seem to have a problem.", 0],
["Why do you need to change the unit price?", 1],
["Could you please tell me the gist of the article you are writing?", 1],
["Would you mind sending or faxing your request to me?", 1],
["About when are you publishing this book?", 1],
["May I record the interview?", 1]
]
実装は下記になります。
今回は無難にLSTMを用いて、出力した隠れ層ベクトルから分類判断してみるようにネットワークを構成してみました。
GitHub: https://github.com/Gin04gh/nlp/blob/master/LSTM_SentenceClassifier.ipynb
移設しました。
import re
import numpy as np
import chainer
from chainer import Chain, optimizers, training
from chainer.training import extensions
import chainer.functions as F
import chainer.links as L
# モデルクラスの定義
class LSTM_SentenceClassifier(Chain):
def __init__(self, vocab_size, embed_size, hidden_size, out_size):
# クラスの初期化
# :param vocab_size: 単語数
# :param embed_size: 埋め込みベクトルサイズ
# :param hidden_size: 隠れ層サイズ
# :param out_size: 出力層サイズ
super(LSTM_SentenceClassifier, self).__init__(
# encode用のLink関数
xe = L.EmbedID(vocab_size, embed_size, ignore_label=-1),
eh = L.LSTM(embed_size, hidden_size),
hh = L.Linear(hidden_size, hidden_size),
# classifierのLink関数
hy = L.Linear(hidden_size, out_size)
)
def __call__(self, x):
# 順伝播の計算を行う関数
# :param x: 入力値
# エンコード
x = F.transpose_sequence(x)
self.eh.reset_state()
for word in x:
e = self.xe(word)
h = self.eh(e)
# 分類
y = self.hy(h)
return y
# 学習
N = len(data)
data_x, data_t = [], []
for d in data:
data_x.append(d[0]) # 文書
data_t.append(d[1]) # ラベル
def sentence2words(sentence):
stopwords = ["i", "a", "an", "the", "and", "or", "if", "is", "are", "am", "it", "this", "that", "of", "from", "in", "on"]
sentence = sentence.lower() # 小文字化
sentence = sentence.replace("\n", "") # 改行削除
sentence = re.sub(re.compile(r"[!-\/:-@[-`{-~]"), " ", sentence) # 記号をスペースに置き換え
sentence = sentence.split(" ") # スペースで区切る
sentence_words = []
for word in sentence:
if (re.compile(r"^.*[0-9]+.*$").fullmatch(word) is not None): # 数字が含まれるものは除外
continue
if word in stopwords: # ストップワードに含まれるものは除外
continue
sentence_words.append(word)
return sentence_words
# 単語辞書
words = {}
for sentence in data_x:
sentence_words = sentence2words(sentence)
for word in sentence_words:
if word not in words:
words[word] = len(words)
# 文章を単語ID配列にする
data_x_vec = []
for sentence in data_x:
sentence_words = sentence2words(sentence)
sentence_ids = []
for word in sentence_words:
sentence_ids.append(words[word])
data_x_vec.append(sentence_ids)
# 文章の長さを揃えるため、-1パディングする(系列を覚えておきやすくするため、前パディングする)
max_sentence_size = 0
for sentence_vec in data_x_vec:
if max_sentence_size < len(sentence_vec):
max_sentence_size = len(sentence_vec)
for sentence_ids in data_x_vec:
while len(sentence_ids) < max_sentence_size:
sentence_ids.insert(0, -1) # 先頭に追加
# データセット
data_x_vec = np.array(data_x_vec, dtype="int32")
data_t = np.array(data_t, dtype="int32")
dataset = []
for x, t in zip(data_x_vec, data_t):
dataset.append((x, t))
# 定数
EPOCH_NUM = 10
EMBED_SIZE = 200
HIDDEN_SIZE = 100
BATCH_SIZE = 5
OUT_SIZE = 2
# モデルの定義
model = L.Classifier(LSTM_SentenceClassifier(
vocab_size=len(words),
embed_size=EMBED_SIZE,
hidden_size=HIDDEN_SIZE,
out_size=OUT_SIZE
))
optimizer = optimizers.Adam()
optimizer.setup(model)
# 学習開始
train, test = chainer.datasets.split_dataset_random(dataset, N-20)
train_iter = chainer.iterators.SerialIterator(train, BATCH_SIZE)
test_iter = chainer.iterators.SerialIterator(test, BATCH_SIZE, repeat=False, shuffle=False)
updater = training.StandardUpdater(train_iter, optimizer, device=-1)
trainer = training.Trainer(updater, (EPOCH_NUM, "epoch"), out="result")
trainer.extend(extensions.Evaluator(test_iter, model, device=-1))
trainer.extend(extensions.LogReport(trigger=(1, "epoch")))
trainer.extend(extensions.PrintReport( ["epoch", "main/loss", "validation/main/loss", "main/accuracy", "validation/main/accuracy", "elapsed_time"])) # エポック、学習損失、テスト損失、学習正解率、テスト正解率、経過時間
#trainer.extend(extensions.ProgressBar()) # プログレスバー出力
trainer.run()
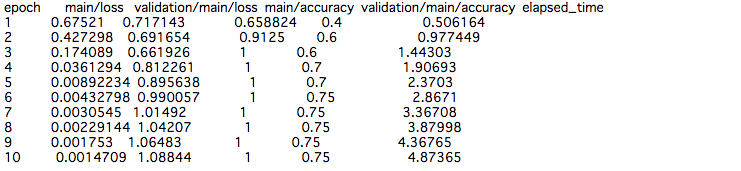
テストデータに対して、正解率0.75程度まで学習できました。
思いっきり過学習していますが笑
このようにして、文章をベクトルとして覚えさせることは、自然言語処理における深層学習の常套手段のようです。
CNNによる文章分類モデル
次にCNNによる文章分類を実装してみます。
仕組みとしては、下記の論文で提案されています。
Mi>Convolutional Neural Networks for Sentence Classification: https://arxiv.org/abs/1408.5882
実は今回はこちらの実装を試してみたくて、やってみた次第です。
イメージとしては下記のように計算します。
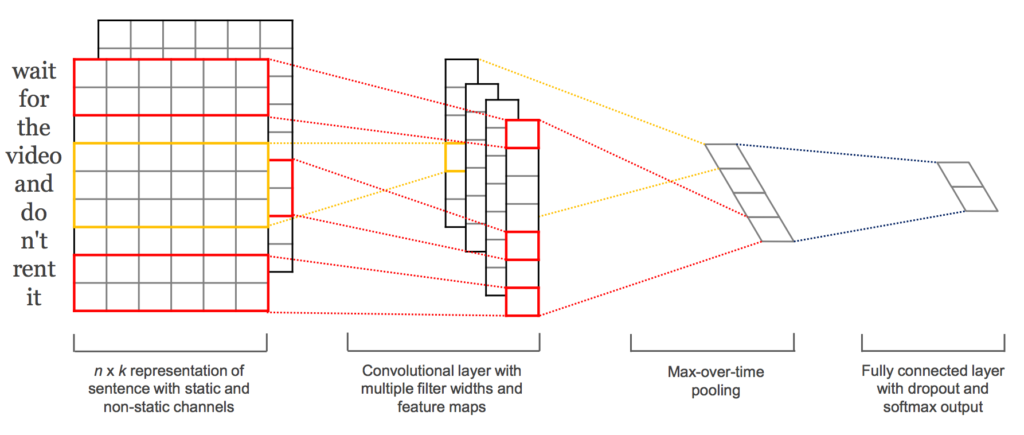
文章は一文字ずつ語彙数分のベクトルのBoWなどに変換をし、縦が文章の単語数、横が語彙数の行列として変換します。
これを畳み込みを行うのですが、フィルター(カーネル)サイズを、縦はN-gram分、横を語彙数分とすることで、N文字ずつBoWベクトルを畳み込みするようなイメージで計算を行います。
このN-gram、つまり何文字ずつ同時に読み込むかを複数パターン配列で渡し、それぞれ畳み込みのベクトルを計算し、分類の時に連結して使うことで、複数のN-gramで読み込んだベクトルを分類の情報に使えるという仕組みのようです。
実装が下記になります。
GitHub: https://github.com/Gin04gh/nlp/blob/master/CNN_SentenceClassifier.ipynb
移設しました。
import re
import numpy as np
import chainer
from chainer import ChainList, optimizers, training
from chainer.training import extensions
import chainer.functions as F
import chainer.links as L
# モデルクラスの定義
class CNN_SentenceClassifier(ChainList):
def __init__(self, in_channel, out_channel, filter_height_list, filter_width, out_size, max_sentence_size):
# クラスの初期化
# :param in_channel: 入力チャネル数
# :param out_channel: 出力チャネル数
# :param filter_height_list: フィルター縦サイズの配列
# :param filter_width: フィルター横サイズ
# :param out_size: 分類ラベル数
# :param max_sentence_size: 文章の長さの最大サイズ
self.filter_height_list = filter_height_list
self.max_sentence_size = max_sentence_size
self.convolution_num = len(filter_height_list)
# Linkの定義
link_list = [L.Convolution2D(in_channel, out_channel, (i, filter_width), pad=0) for i in filter_height_list] # Convolution層用のLinkをフィルター毎に追加
link_list.append(L.Linear(out_channel * self.convolution_num, out_channel * self.convolution_num)) # 隠れ層
link_list.append(L.Linear(out_channel * self.convolution_num, out_size)) # 出力層
# 定義したLinkのリストを用いてクラスを初期化する
super(CNN_SentenceClassifier, self).__init__(*link_list)
def __call__(self, x):
# 順伝播の計算を行う関数
# :param x: 入力値
# フィルタを通した結果を格納する配列
xcs = [None for i in self.filter_height_list]
chs = [None for i in self.filter_height_list]
# フィルタごとにループ
for i, filter_height in enumerate(self.filter_height_list):
xcs[i] = F.relu(self[i](x))
chs[i] = F.max_pooling_2d(xcs[i], (self.max_sentence_size+1-filter_height))
# Convolution+Poolingの結果の結合
h = F.concat(chs, axis=2)
h = F.dropout(F.tanh(self[self.convolution_num+0](h)))
y = self[self.convolution_num+1](h)
return y
# 学習
N = len(data)
data_x, data_t = [], []
for d in data:
data_x.append(d[0]) # 文書
data_t.append(d[1]) # ラベル
def sentence2words(sentence):
stopwords = ["i", "a", "an", "the", "and", "or", "if", "is", "are", "am", "it", "this", "that", "of", "from", "in", "on"]
sentence = sentence.lower() # 小文字化
sentence = sentence.replace("\n", "") # 改行削除
sentence = re.sub(re.compile(r"[!-\/:-@[-`{-~]"), " ", sentence) # 記号をスペースに置き換え
sentence = sentence.split(" ") # スペースで区切る
sentence_words = []
for word in sentence:
if (re.compile(r"^.*[0-9]+.*$").fullmatch(word) is not None): # 数字が含まれるものは除外
continue
if word in stopwords: # ストップワードに含まれるものは除外
continue
sentence_words.append(word)
return sentence_words
# 単語辞書
words = {}
for sentence in data_x:
sentence_words = sentence2words(sentence)
for word in sentence_words:
if word not in words:
words[word] = len(words)
# 文章を単語ベクトル配列にする
data_x_vec = []
for sentence in data_x:
sentence_words = sentence2words(sentence)
sentence_vec = []
for word in sentence_words:
word_vec = np.zeros((len(words)))
word_vec[words[word]] = 1
sentence_vec.append(word_vec)
data_x_vec.append(sentence_vec)
# 文章の長さを揃えるため、ゼロパディングする
max_sentence_size = 0
for sentence_vec in data_x_vec:
if max_sentence_size < len(sentence_vec):
max_sentence_size = len(sentence_vec)
for sentence_vec in data_x_vec:
while len(sentence_vec) < max_sentence_size:
sentence_vec.append(np.zeros((len(words))))
# データセット
data_x_vec = np.array(data_x_vec, dtype="float32")
data_t = np.array(data_t, dtype="int32")
dataset = []
for x, t in zip(data_x_vec, data_t):
dataset.append((x.reshape(1, max_sentence_size, len(words)), t))
# 定数
EPOCH_NUM = 10
BATCH_SIZE = 5
OUT_SIZE = 2
FILTER_HEIGHT_LIST = [1,2,3]
OUT_CHANNEL = 32
# モデルの定義
model = L.Classifier(CNN_SentenceClassifier(
in_channel=1,
out_channel=OUT_CHANNEL,
filter_height_list=FILTER_HEIGHT_LIST,
filter_width=len(words),
out_size=OUT_SIZE,
max_sentence_size=max_sentence_size
))
optimizer = optimizers.Adam()
optimizer.setup(model)
# 学習開始
train, test = chainer.datasets.split_dataset_random(dataset, N-20)
train_iter = chainer.iterators.SerialIterator(train, BATCH_SIZE)
test_iter = chainer.iterators.SerialIterator(test, BATCH_SIZE, repeat=False, shuffle=False)
updater = training.StandardUpdater(train_iter, optimizer, device=-1)
trainer = training.Trainer(updater, (EPOCH_NUM, "epoch"), out="result")
trainer.extend(extensions.Evaluator(test_iter, model, device=-1))
trainer.extend(extensions.LogReport(trigger=(1, "epoch")))
trainer.extend(extensions.PrintReport( ["epoch", "main/loss", "validation/main/loss", "main/accuracy", "validation/main/accuracy", "elapsed_time"])) # エポック、学習損失、テスト損失、学習正解率、テスト正解率、経過時間
#trainer.extend(extensions.ProgressBar()) # プログレスバー出力
trainer.run()
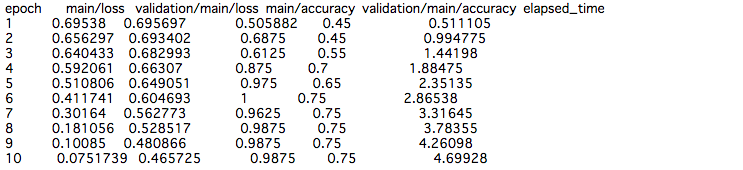
こちらも、テストデータに対する正解度は0.75程度まで上がりました。
LSTMの時と同様、過学習してしまっているようですが、ひとまず、文章分類のアルゴリズムが理解できました。
まとめ
以上、LSTMとCNNでの文章分類をそれぞれ実装し、違いを確認してみました。
LSTMは単純な単方向でしたが、双方向にしたり、Attentionを追加するなどして、精度を向上させたりすることが考えられます。
CNNでも、今回はN-gramを1,2,3としましたが、もっと増やしみたり、またAttentionを追加してみるなども考えられます。
究極的には、両方合わせるとかも考えられなくはないでしょうけど、計算とかやばそう。
しかし今回のタスクでは、どちらにしても有効みたいですので、どのようなタスクにおいて、どちらが有効なのかといったところも気になりました。
コメント
学習データに間違いがあるようです。
同一文章が重複しており、片側に疑問文とラベル付けされています。
> [“Great, see you tomorrow then.”, 0],
> [“Great, see you tomorrow then.”, 1],
これは失礼致しました;;
ご指摘ありがとうございます!!