今回は、以下の論文の文章分散表現、Sparse Composite Document Vectors; SCDVについて書きます。
SCDV : Sparse Composite Document Vectors using soft clustering over distributional representations: https://arxiv.org/abs/1612.06778
実は去年に試しに実装していたのですが、他にネタがないためまだ投稿していませんでしたので、書こうと思います。
SCDVについて
SCDVは、文章ベクトルを取得する方法の1つです。
文章ベクトルを取得する手法はDoc2Vecなど色々ありますが、論文において、取得した文章ベクトルを用いたマルチラベル分類では、他の方法よりも高い精度を出せているようです。
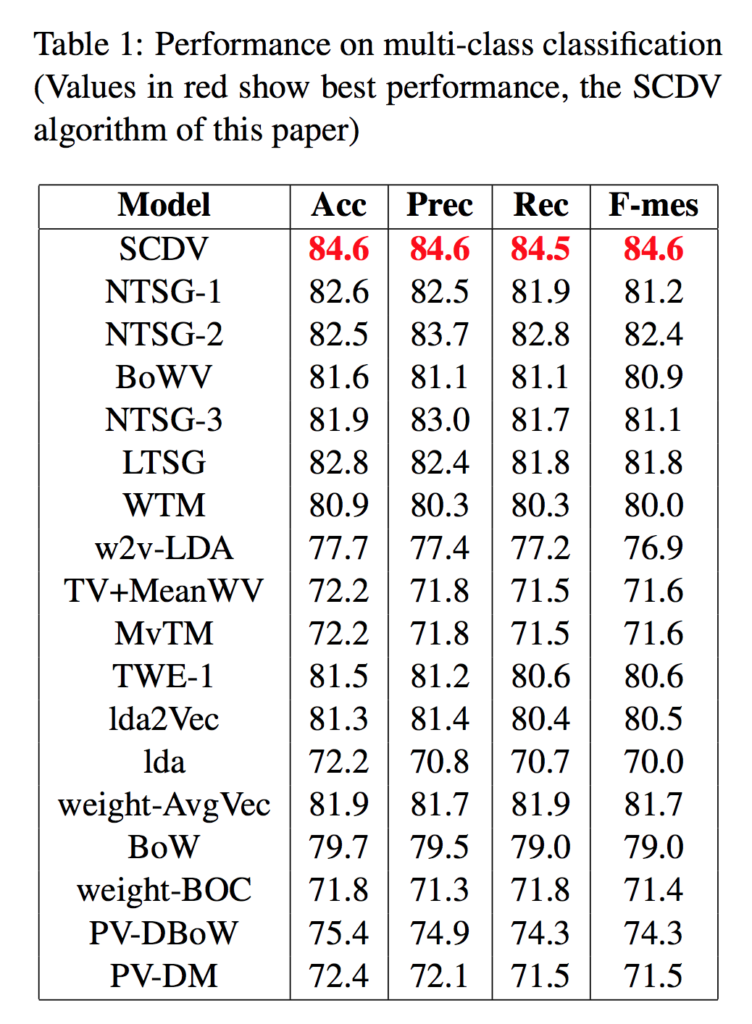
うーむ、ていうか、NTSGってのはなんだ。
すでにここに並べられているモデルさえ、知らないものが多いですが、一旦無視しましょう。
SCDVの方法はそこまで難しくないようです。

文章データから得られる全単語について、Word2Vecベクトルとidf値を計算しておきます。
この単語ベクトルについて、混合ガウスモデルで  クラス分類に学習し、一つ一つの単語ベクトルが各クラスに属する予測確率を単語ベクトルにかけて連結して、単語ベクトル数*クラスタ数に次元を広げるようなことをします。
クラス分類に学習し、一つ一つの単語ベクトルが各クラスに属する予測確率を単語ベクトルにかけて連結して、単語ベクトル数*クラスタ数に次元を広げるようなことをします。
これにidf値をかけたものが、単語ベクトル Word-topics vector になります。
これを、文章の構成単語について平均をとって、スパースさせたものを、文章ベクトルとして扱います。
実装
実装は以下のGitHubにもあげました。
GitHub: https://github.com/Gin04gh/datascience/blob/master/news_corpus/scdv.ipynb
今回は論文と同じくニュースコーパスのデータを使いました。
ただし、20クラスも分類していると時間がかかるので、5クラス分だけ取得してきて、分散表現のt-SNEの可視化の確認や、分類モデルに使った時の精度の比較を行いました。
準備として、ライブラリをインポートと、scikit-learnからニュースコーパスをダウンロードします。
import re
import numpy as np
import pandas as pd
import matplotlib
import matplotlib.pylab as plt
import seaborn as sns
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
from sklearn import datasets, manifold, mixture, model_selection
from gensim.models import Word2Vec
from gensim.models.doc2vec import Doc2Vec, TaggedDocument
from xgboost import XGBClassifier
categories = [
'alt.atheism',
'comp.graphics',
'rec.sport.baseball',
'sci.space',
'talk.politics.guns'
]
train = datasets.fetch_20newsgroups(subset='train', categories=categories)
train.data = np.array(train.data, dtype=np.object)
選んだカテゴリは適当です。
それぞれ
for i, c in enumerate(categories):
indices = np.where(train.target == i)
print(c + ':\t{}'.format(len(train.data[indices])))
"""
alt.atheism: 480
comp.graphics: 584
rec.sport.baseball: 597
sci.space: 593
talk.politics.guns: 546
"""
の件数分のニュースデータがあり、計2,800件の文章データになります。
また、以下のパラメータを決めておきます。
# BoW, tf-idf, average Word2Vec, Doc2Vec, SCDV
features_num = 200
min_word_count = 10
context = 5
downsampling = 1e-3
epoch_num = 10
いずれの分散表現も文章を単語に分解して作成します。
その時の文章から単語へ分解する関数を用意しておきます。
def analyzer(text):
stop_words = ['i', 'a', 'an', 'the', 'to', 'and', 'or', 'if', 'is', 'are', 'am', 'it', 'this', 'that', 'of', 'from', 'in', 'on']
text = text.lower() # 小文字化
text = text.replace('\n', '') # 改行削除
text = text.replace('\t', '') # タブ削除
text = re.sub(re.compile(r'[!-\/:-@[-`{-~]'), ' ', text) # 記号をスペースに置き換え
text = text.split(' ') # スペースで区切る
words = []
for word in text:
if (re.compile(r'^.*[0-9]+.*$').fullmatch(word) is not None): # 数字が含まれるものは除外
continue
if word in stop_words: # ストップワードに含まれるものは除外
continue
if len(word) < 2: # 1文字、0文字(空文字)は除外
continue
words.append(word)
return words
ストップワードはもっと他にもたくさん入れるべきでしょうが、ひとまずはこのくらいで。
BoW
まずは一番基礎的なBoWで文章の特徴量を表した場合について。
この辺りは sklearn.feature_extraction.text で特徴量作成が用意されているので、積極的に使っていきます。
corpus = train.data
count_vectorizer = CountVectorizer(analyzer=analyzer, min_df=min_word_count, binary=True)
bows = count_vectorizer.fit_transform(corpus)
bows.shape # (2800, 5445)
これをt-SNEで二次元に圧縮して、可視化してみます。
tsne_bow = manifold.TSNE(n_components=2).fit_transform(bows.toarray())
tsne_bow.shape # (2800, 2)
df_tsne_bow = pd.DataFrame({
'x': tsne_bow[:, 0],
'y': tsne_bow[:, 1],
'category': train.target,
})
df_tsne_bow.plot.scatter(x='x', y='y', c='category', colormap='viridis', figsize=(7, 5), s=20)
plt.show()
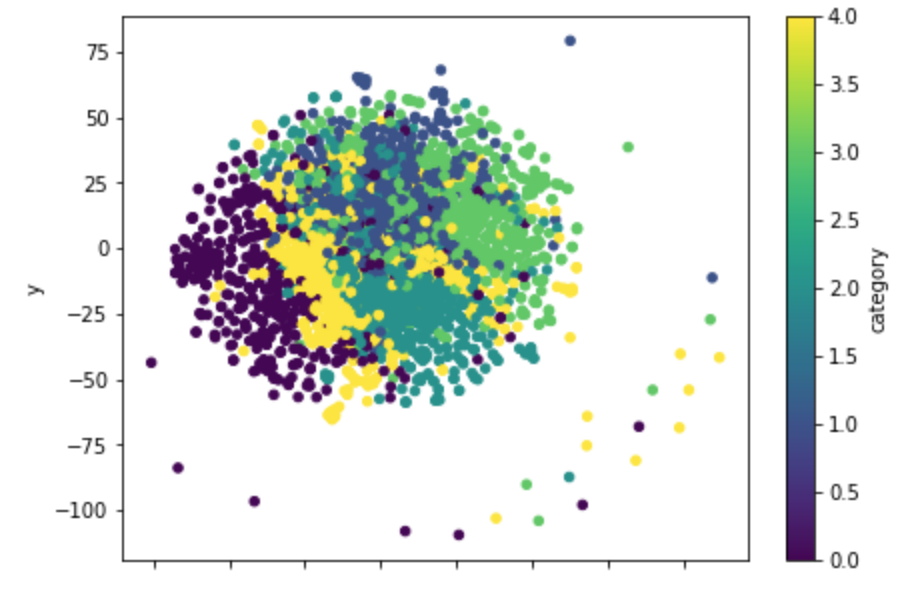
このカラーマップだと、カテゴリごとに綺麗に色が分かれてくれるので見やすいです。
この図では、あまり分かれてくれていないように見えますね。
tf-idf
次にTf-Idfです。
これも sklearn.feature_extraction.text に関数が用意されていますので、すぐ作成できます。
corpus = train.data
tfidf_vectorizer = TfidfVectorizer(analyzer=analyzer, min_df=min_word_count)
tfidfs = tfidf_vectorizer.fit_transform(corpus)
tfidfs.shape # (2800, 5445)
tsne_tfidf = manifold.TSNE(n_components=2).fit_transform(tfidfs.toarray())
tsne_tfidf.shape # (2800, 2)
df_tsne_tfidf = pd.DataFrame({
'x': tsne_tfidf[:, 0],
'y': tsne_tfidf[:, 1],
'category': train.target,
})
df_tsne_tfidf.plot.scatter(x='x', y='y', c='category', colormap='viridis', figsize=(7, 5), s=20)
plt.show()
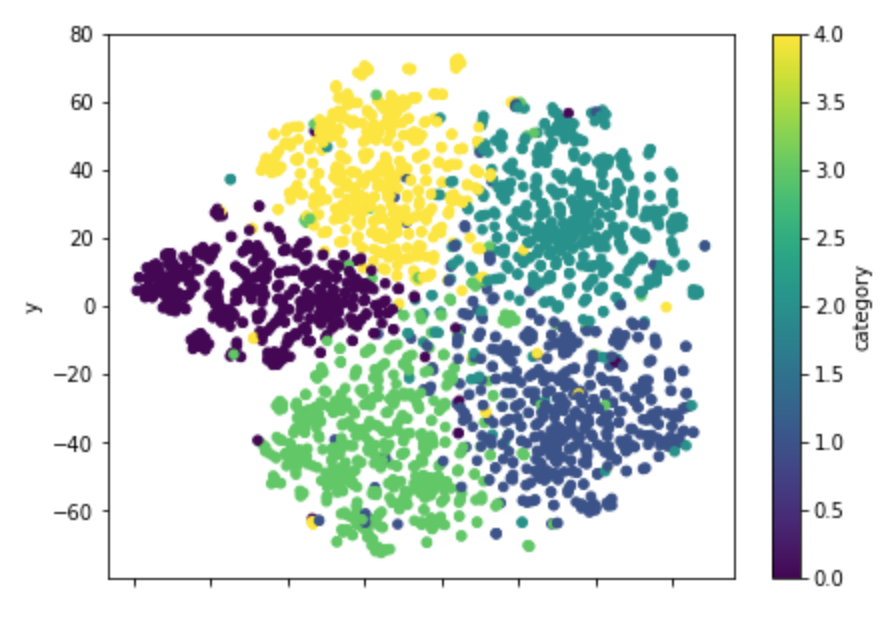
かなり綺麗に分かれてくれているように見えます。
Word2Vec (Average)
Word2Vecは単語ベクトルですが、文章に含まれる単語をこのベクトルで計算して、平均など集約することで文章ベクトルとする方法も、文章の分散表現としてよく利用されます。
Word2Vecは gensim で簡単に学習、ベクトルの変換が可能です。
今回はWord2Vecモデルで表される単語ベクトルの平均(Average)をとって文章ベクトルとしました。
corpus = [analyzer(text) for text in train.data]
word2vecs = Word2Vec(
sentences=corpus, iter=epoch_num, size=features_num,
min_count=min_word_count, window=context, sample=downsampling,
)
avg_word2vec = np.array([word2vecs.wv[list(analyzer(text) & word2vecs.wv.vocab.keys())].mean(axis=0) for text in train.data])
avg_word2vec.shape # (2800, 200)
ベクトルの次元数は先ほどのハイパーパラメータで決定した通り、200次元としました。
あとは同様にt-SNEで圧縮して、可視化できます。
tsne_avg_word2vec = manifold.TSNE(n_components=2).fit_transform(avg_word2vec)
tsne_avg_word2vec.shape # (2800, 2)
df_tsne_avg_word2vec = pd.DataFrame({
'x': tsne_avg_word2vec[:, 0],
'y': tsne_avg_word2vec[:, 1],
'category': train.target,
})
df_tsne_avg_word2vec.plot.scatter(x='x', y='y', c='category', colormap='viridis', figsize=(7, 5), s=20)
plt.show()
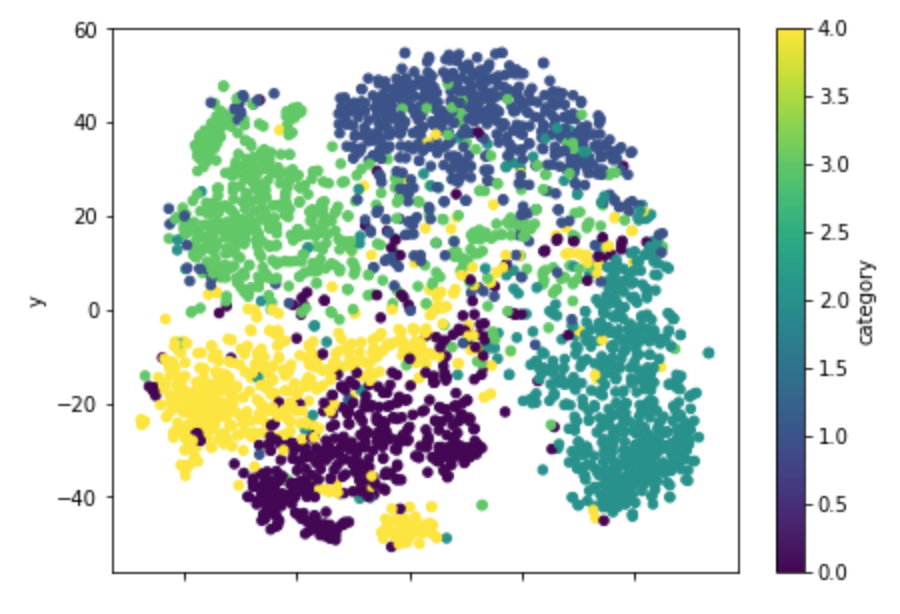
これも割と文章のラベルごとに分かれてくれているようです。
同じクラスだけども、さらに別の集団として捉えているようなものも見られます。
ちなみに、書籍で『ゼロから作るDeep Learning』の第2弾が最近登場しており、内容は自然言語処理メインになっていて、Word2Vecの解説なども分かりやすく書いているのでおすすめです。

内容は深層学習に寄っているので、RNNや系列変換モデルについても書いてあります。
系列変換モデルは以前に投稿しているので、よかったら参考にどうぞ。
http://www.ie110704.net/2017/08/21/attention-seq2seq%E3%81%A7%E5%AF%BE%E8%A9%B1%E3%83%A2%E3%83%87%E3%83%AB%E3%82%92%E5%AE%9F%E8%A3%85%E3%81%97%E3%81%A6%E3%81%BF%E3%81%9F/
Doc2Vec
文章の分散表現なので、そのまんま、Doc2Vecも試してみます。
こちらも gensim から利用可能。
この辺りの自然言語処理に関しては、scikit-learn と gensim のおかげでコードもかなりスッキリと書けるようになりました。
corpus = [TaggedDocument(words=analyzer(text), tags=[i]) for i, text in enumerate(train.data)]
doc2vecs = Doc2Vec(
documents=corpus, dm=1, epochs=epoch_num, vector_size=features_num,
min_count=min_word_count, window=context, sample=downsampling
) # dm == 1 -> dmpv, dm != 1 -> DBoW
doc2vecs = np.array([doc2vecs.infer_vector(analyzer(text)) for text in train.data])
doc2vecs.shape # (2800, 200)
tsne_doc2vec = manifold.TSNE(n_components=2).fit_transform(doc2vecs)
tsne_doc2vec.shape # (2800, 2)
df_tsne_doc2vec = pd.DataFrame({
'x': tsne_doc2vec[:, 0],
'y': tsne_doc2vec[:, 1],
'category': train.target,
})
df_tsne_doc2vec.plot.scatter(x='x', y='y', c='category', colormap='viridis', figsize=(7, 5), s=20)
plt.show()
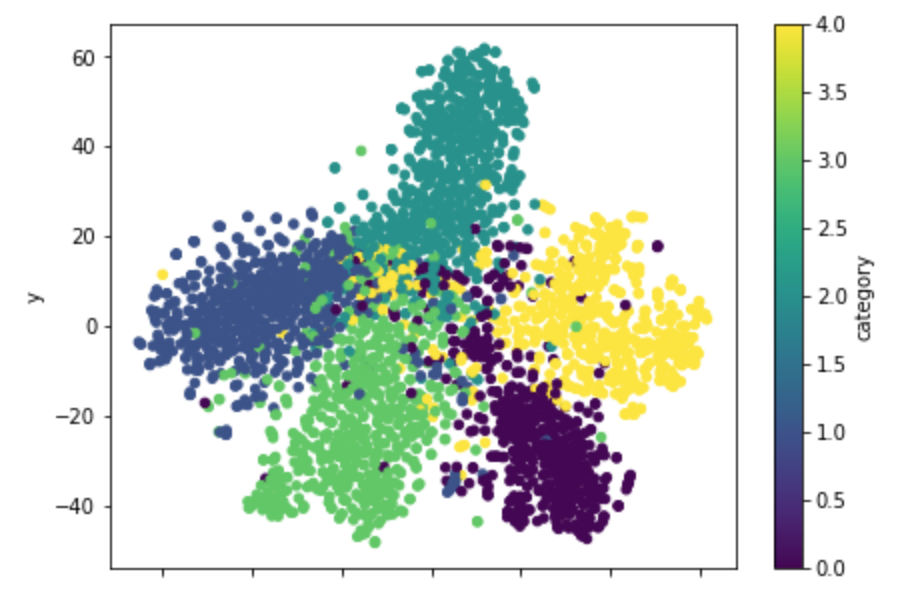
なんかお花みたいで綺麗。
ただ、他の分散表現もそうですが、一定数、うまく分かれてくれていない文章が中心辺りに集まって見られるようですね。
SCDV
ここまで、様々な文章ベクトルを表してきました。
SCDVについて同様にやってみます。
論文で実装が公開されていますので、こちらも参考にしながら書いてみます。
- https://github.com/dheeraj7596/SCDV
まずは、全ての単語ベクトルを混合ガウスモデルで学習してクラスタリングします。
論文においては、このクラスタ数を変化させた時に、どのように分類モデルの精度が変化するかを調査しています。
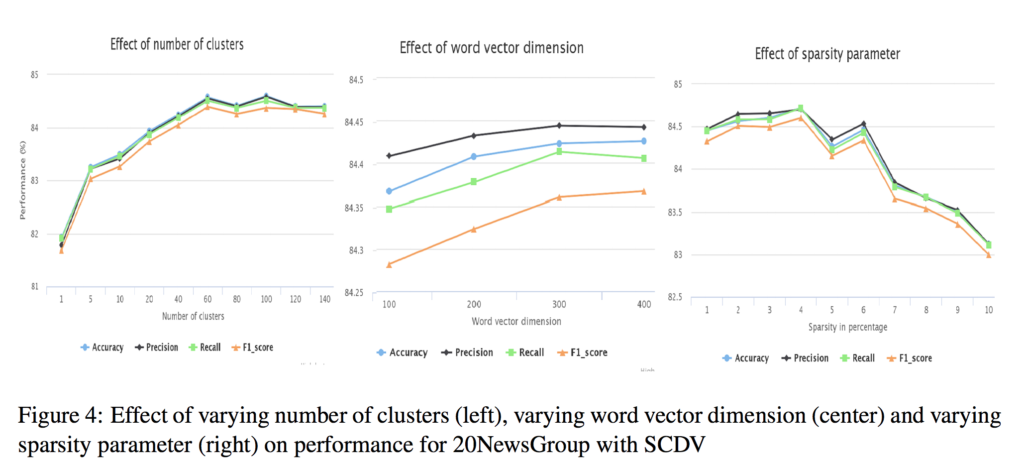
これを見る限り、クラスタ数が60以上からは、あまり変化がないように見えますので、クラスタ数は60としました。
後述になりますが、sparsityは4%。
ベクトル次元数は300の方が良いようですが、今回はなぜ200にしているのかというと、単純に間違えました。←
word_vectors = word2vecs.wv.vectors
clusters_num = 60
gmm = mixture.GaussianMixture(n_components=clusters_num, covariance_type='tied', max_iter=50)
gmm.fit(word_vectors)
次に、Word-topics vectorを作成します。
単語ごとに、単語ベクトルと各クラスの予測確率、idf値を掛け合わせます。
idf_dic = dict(zip(tfidf_vectorizer.get_feature_names(), tfidf_vectorizer._tfidf.idf_))
assign_dic = dict(zip(word2vecs.wv.index2word, gmm.predict(word_vectors)))
soft_assign_dic = dict(zip(word2vecs.wv.index2word, gmm.predict_proba(word_vectors)))
word_topic_vecs = {}
for word in assign_dic:
word_topic_vecs[word] = np.zeros(features_num*clusters_num, dtype=np.float32)
for i in range(0, clusters_num):
try:
word_topic_vecs[word][i*features_num:(i+1)*features_num] = word2vecs.wv[word]*soft_assign_dic[word][i]*idf_dic[word]
except:
continue
出来上がった Word-topics vector を用いて、文章ごとにベクトルを作成します。
scdvs = np.zeros((len(train.data), clusters_num*features_num), dtype=np.float32)
a_min = 0
a_max = 0
for i, text in enumerate(train.data):
tmp = np.zeros(clusters_num*features_num, dtype=np.float32)
words = analyzer(text)
for word in words:
if word in word_topic_vecs:
tmp += word_topic_vecs[word]
norm = np.sqrt(np.sum(tmp**2))
if norm > 0:
tmp /= norm
a_min += min(tmp)
a_max += max(tmp)
scdvs[i] = tmp
p = 0.04
a_min = a_min*1.0 / len(train.data)
a_max = a_max*1.0 / len(train.data)
thres = (abs(a_min)+abs(a_max)) / 2
thres *= p
scdvs[abs(scdvs) < thres] = 0
scdvs.shape # (2800, 12000)
tsne_scdv = manifold.TSNE(n_components=2).fit_transform(scdvs)
tsne_scdv.shape # (2800, 2)
df_tsne_scdv = pd.DataFrame({
'x': tsne_scdv[:, 0],
'y': tsne_scdv[:, 1],
'category': train.target,
})
df_tsne_scdv.plot.scatter(x='x', y='y', c='category', colormap='viridis', figsize=(7, 5), s=20)
plt.show()
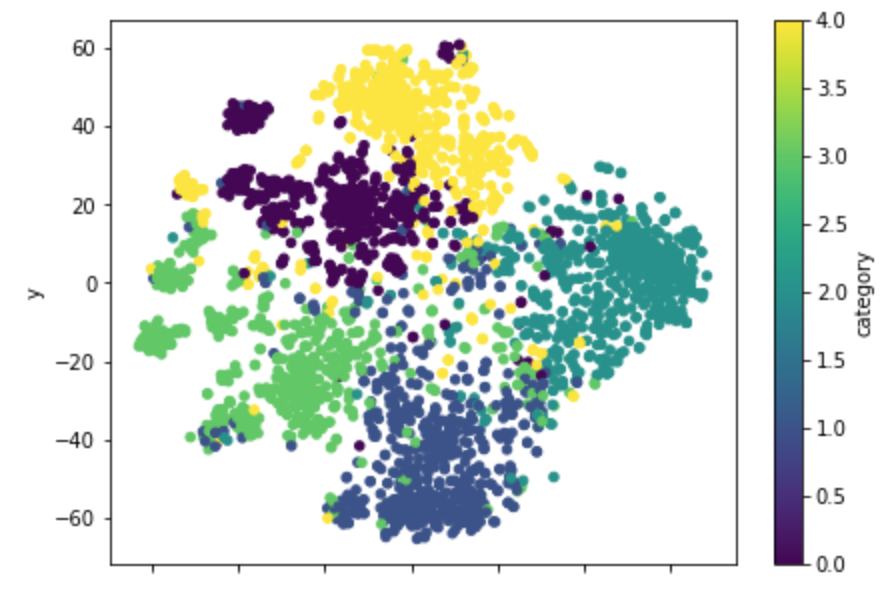
ふむり。
同クラス内でさらに特徴的な文章の分類を表現できるようになっているような気がします。
ただ、やっぱり微妙にうまく分かれてくれない文章はちらほらいるようで、元々難しい文章については同様に難しい感じなんですかね。
XGBoostで分類精度を比較
さて、これを分類モデルに突っ込んで精度を確認してみます。
論文でもSVMで同様に調べていますが、今回はXGBoostを使ってみました。
model = XGBClassifier()
df_compare = pd.DataFrame(columns=['name', 'train_accuracy', 'valid_accuracy', 'time'])
scoring = ['accuracy']
cv_trial_num = 8
# BoW
cv_rlts = model_selection.cross_validate(model, bows.toarray(), train.target, scoring=scoring, cv=cv_trial_num, return_train_score=True)
for i in range(cv_trial_num):
s = pd.Series(['BoW', cv_rlts['train_accuracy'][i], cv_rlts['test_accuracy'][i], cv_rlts['fit_time'][i]], index=df_compare.columns, name='BoW'+str(i))
df_compare = df_compare.append(s)
# tfidf
cv_rlts = model_selection.cross_validate(model, tfidfs.toarray(), train.target, scoring=scoring, cv=cv_trial_num, return_train_score=True)
for i in range(cv_trial_num):
s = pd.Series(['tfidf', cv_rlts['train_accuracy'][i], cv_rlts['test_accuracy'][i], cv_rlts['fit_time'][i]], index=df_compare.columns, name='tfidf'+str(i))
df_compare = df_compare.append(s)
# Word2Vec average
cv_rlts = model_selection.cross_validate(model, avg_word2vec, train.target, scoring=scoring, cv=cv_trial_num, return_train_score=True)
for i in range(cv_trial_num):
s = pd.Series(['avg_Word2Vec', cv_rlts['train_accuracy'][i], cv_rlts['test_accuracy'][i], cv_rlts['fit_time'][i]], index=df_compare.columns, name='avg_Word2Vec'+str(i))
df_compare = df_compare.append(s)
# Doc2Vec
cv_rlts = model_selection.cross_validate(model, doc2vecs, train.target, scoring=scoring, cv=cv_trial_num, return_train_score=True)
for i in range(cv_trial_num):
s = pd.Series(['Doc2Vec', cv_rlts['train_accuracy'][i], cv_rlts['test_accuracy'][i], cv_rlts['fit_time'][i]], index=df_compare.columns, name='Doc2Vec'+str(i))
df_compare = df_compare.append(s)
# SCDV
cv_rlts = model_selection.cross_validate(model, scdvs, train.target, scoring=scoring, cv=cv_trial_num, return_train_score=True)
for i in range(cv_trial_num):
s = pd.Series(['SCDV', cv_rlts['train_accuracy'][i], cv_rlts['test_accuracy'][i], cv_rlts['fit_time'][i]], index=df_compare.columns, name='SCDV'+str(i))
df_compare = df_compare.append(s)
plt.figure(figsize=(12,5))
sns.boxplot(data=df_compare, y='name', x='valid_accuracy', orient='h', palette='viridis', linewidth=0.5, width=0.5)
plt.grid()
plt.title('validation accuracy')
plt.show()
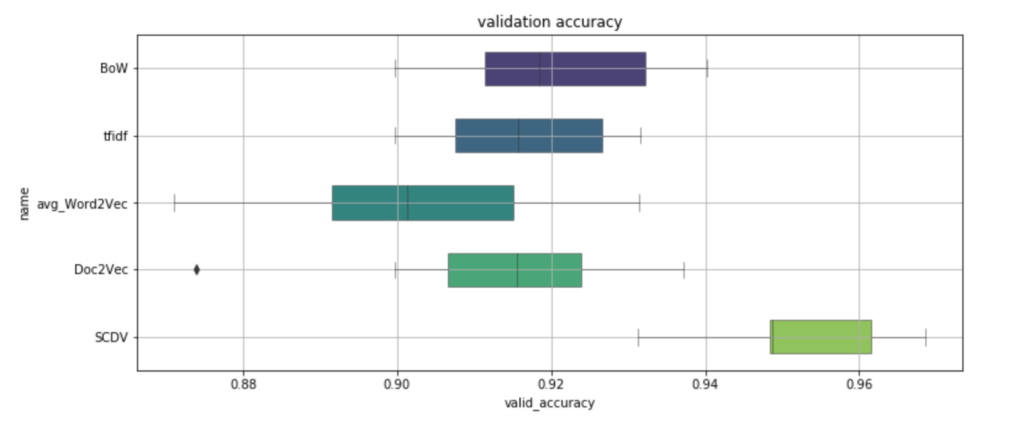
おお、SCDVだけ頭一つ抜けていますね。
誤差でたまにBoWやDoc2Vecに劣ることもあるようですが、全体的には精度が上がっているように見受けられます。
むしろこれ見て意外だったのが、BoWがSCDV以外の他の手法に対して良いという点だったり。
可視化ではだいぶ潰されてしまったように見えましたが、潰されたベクトルに良い感じのがあったのでしょうか。
まとめ
SCDVについて書きました。
論文も今回も20newsコーパスデータですが、分類精度の向上が見られました。
もちろんこの辺りはどんな方法でも文章データがどういうものかに依存する部分はあるかと思いますが、実装も難しくありませんし、データに対して様々な文章ベクトルを試して判断すると良いと思います。
コメント